Timeouts for Serverless Workflow
Serverless Workflow specification defines a wide amount of possible timeout configurations. Among them, Kogito currently supports workflow and event timeouts.
Regardless of its application scope (workflow or state), you can not define the timeouts as a specific point in time, but they should be an amount of time, a duration, which is considered to start when the referred scope becomes active. Timeouts use the ISO 8601 data and time standard to specify a duration of time.
It follows the format PnDTnHnMn.nS with days considered to be exactly 24 hours.
For instance, PT15M configures 15 minutes, and P2DT3H4M defines 2 days, 3 hours and 4 minutes.
Workflow timeout
You can set up the maximum amount of time a workflow might be running before being canceled. This is configured in the header section of the flow, by using the WorkflowExecTimeout definition. Only the duration property is currently implemented.
Once canceled, the workflow is considered to be finished and will not be accessible through a GET request anymore. So it behaves as if the interrupt was true by default.
For example, in order to cancel the workflow after an hour of execution, you might add the following snippet.
"timeouts": {
"workflowExecTimeout": "PT1H"
}Event timeout
When you define a state in a serverless workflow, you can use the timeouts property to configure the maximum time to complete this state.
When that time is overdue, the state is considered timed-out, and the engine continues the execution from this state. The execution flow depends on the state type, for instance,
a transition to a next state.
All the properties you can use to configure state timeouts are described in the Serverless Workflow specification.
Event-based states can use the sub-property eventTimeout to configure the maximum time to wait for an event to arrive.
Callback state timeout
Callback state can be used when you need to execute an action, in general to call an external service, and wait for an asynchronous response in form of an event, the callback.
Once the response event is consumed, the workflow continues the execution, in general moving to the next state defined in the `transition property. See more on Callback state in Serverless Workflow.
Since the callback state halts the execution util the event is consumed, you can define an eventTimeout for it, and in case the event does not arrive in the defined duration time, the workflow continues the execution moving to the next state defined in the transition, see the example.
{
"name": "CallbackState",
"type": "callback",
"action": {
"name": "callbackAction",
"functionRef": {
"refName": "callbackFunction",
"arguments": {
"input": "${\"callback-state-timeouts: \" + $WORKFLOW.instanceId + \" has executed the callbackFunction.\"}"
}
}
},
"eventRef": "callbackEvent",
"transition": "CheckEventArrival",
"onErrors": [
{
"errorRef": "callbackError",
"transition": "FinalizeWithError"
}
],
"timeouts": {
"eventTimeout": "PT30S"
}
}Switch state timeout
The switch state can be used when you need to take an action based on conditions, defined with the eventConditions property, where the workflow execution waits to make a decision depending on the events to be consumed and matched, defined through event definition.
In this situation, you can define an event timeout, that controls the maximum time to wait for an event to match the conditions, if this time is expired, the workflow moves to the state defined in the defaultCondition property of the switch state, as you can see in the example.
See more details about this state on the Serverless Workflow specification.
{
"name": "ChooseOnEvent",
"type": "switch",
"eventConditions": [
{
"eventRef": "visaApprovedEvent",
"transition": "ApprovedVisa"
},
{
"eventRef": "visaDeniedEvent",
"transition": "DeniedVisa"
}
],
"defaultCondition": {
"transition": "HandleNoVisaDecision"
},
"timeouts": {
"eventTimeout": "PT5S"
}
}Event state timeout
The event state is used to wait for one or more events to be received by the workflow and then continue the execution.
If the event state is a starting state, a new workflow instance is created.
|
The event state is not supported as a starting state if the |
The timeouts property is used for this state to configure the maximum time the workflow should wait for the defined events to arrive.
If this time is exceeded and the events are not received, the workflow moves to the state defined in the transition property or ends the workflow instance without performing any actions in case of an end state.
You can see this in the example.
For more information about event state timeout, see Serverless Workflow specification.
{
"name": "WaitForEvent",
"type": "event",
"onEvents": [
{
"eventRefs": [
"event1"
],
"eventDataFilter": {
"data": "${ \"The event1 was received.\" }",
"toStateData": "${ .exitMessage }"
},
"actions": [
{
"name": "printAfterEvent1",
"functionRef": {
"refName": "systemOut",
"arguments": {
"message": "${\"event-state-timeouts: \" + $WORKFLOW.instanceId + \" executing actions for event1.\"}"
}
}
}
]
},
{
"eventRefs": [
"event2"
],
"eventDataFilter": {
"data": "${ \"The event2 was received.\" }",
"toStateData": "${ .exitMessage }"
},
"actions": [
{
"name": "printAfterEvent2",
"functionRef": {
"refName": "systemOut",
"arguments": {
"message": "${\"event-state-timeouts: \" + $WORKFLOW.instanceId + \" executing actions for event2.\"}"
}
}
}
]
}
],
"timeouts": {
"eventTimeout": "PT30S"
},
"transition": "PrintExitMessage"
}Deploying a timed-based workflow
In order to deploy a workflow that contains timeouts or any other timer-based action, it is necessary to have Job Service running in your environment, which is an external service responsible to control the workflows timers, see the section for more information. In the timeout example you can see the details of how set up a Knative infrastructure with the workflow and job service running.
Job Service configuration
All timer-related actions that might be declared in a workflow, are handled by a supporting service, called Job Service, which is responsible for managing, scheduling, and firing all actions (jobs) to be executed in the workflows.
Suppose the workflow service is not configured to use job service or there is no such service running. In that case, all timer-related actions use an embedded in-memory implementation of job service, which should not be used in production, since when the application shutdown, all timers are lost, which in a serverless architecture is a very common behavior with the scale to zero approach. That said, the no job service configuration can only be used for testing or development, but not for production.
The main goal of the Job Service is to work with only active jobs. The Job Service tracks only the jobs that are scheduled and that need to be executed. When a job reaches a final state, the job is removed from the Job Service.
When configured in your environment, all the jobs information and status changes are sent to the Kogito Data
Index Service, where they can be indexed and made available by GraphQL queries.
|
Data index service and the support for jobs information will be available in future releases. |
Job Service persistence
An important configuration aspect of job service is the persistence mechanism, where all job information is stored in a database that makes this information durable upon service restarts and guarantees no information is lost.
PostgreSQL
PostgreSQL is the recommended database to use with job service. Additionally, it provides an initialization procedure that integrates Flyway for the database initialization. It automatically controls the database schema, in this way all tables are created by the service.
In case you need to externally control the database schema, you can check the Flyway SQL scripts in migration and apply them.
You need to set the proper configuration parameters when starting job service. The example shows how to run PostgreSQL as a Kubernetes deployment, but you can run it the way it fits in your environment, the important part is to set all the configuration parameters points to your running instance of PostgreSQL.
Job service leader election
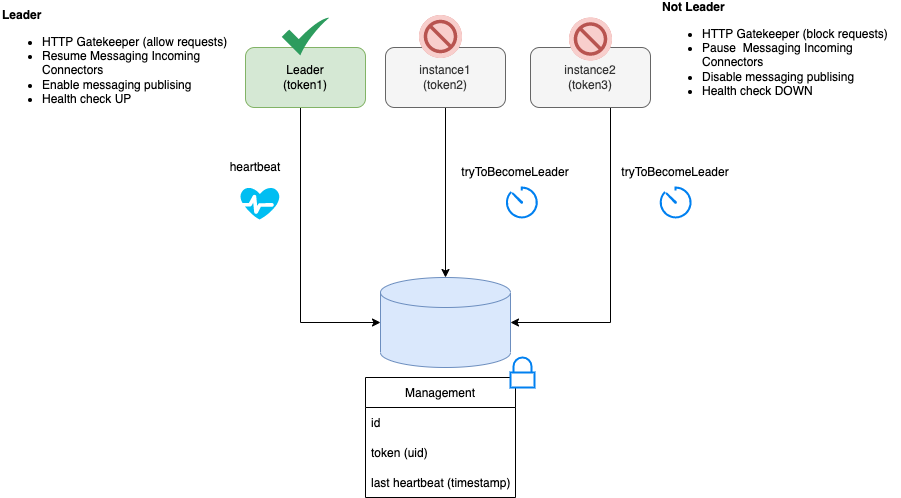
Currently, job service works in a single instance manner where there should be just one active instance of the service.
To avoid issues when deploying the service in the cloud, where it is common to eventually have more than one instance deployed, the job service supports a leader instance election process. Only the instance that become the leader activates the external communication to receive and schedule jobs.
All instances who are not leaders, stay inactive in a kind of wait state and try to become the leader continuously.
Non leader instances stays inactive, in a kind of wait state where they try to become the leader continuously.
When a new instance of the service is started it is not set as a leader at startup time but instead, it starts the process to become one.
When an instance that is the leader for any issue stays irresponsive or it is shut down, one of the other running instances becomes the leader.
|
This leader election mechanism uses the underlying persistence backend, which currently is only supported in the PostgreSQL implementation. |
There is no need for any configuration to support this feature, the only requirement is to have the supported database with the data schema up-to-date as described in PostgreSQL. up-to-date as described in PostgreSQL.
In case the underlying persistence does not support this feature, you should guarantee that just one single instance of job service is running at the same time.
Job Service communication
|
The Job Service does not execute a job but triggers a callback that might be an HTTP request or a Cloud Event that is managed by the configured jobs addon in the workflow application. |
Knative Eventing
To configure the communication between the Job Service and the workflow runtime through the Knative eventing system, you must provide a set of configurations.
The Job Service configuration is done through the deployment descriptor shown in the example.
Addon configuration in the workflow runtime
The communication from the workflow application with Job Service is done through an addon, which is responsible for publishing and consuming events related to timers.
When you run the workflow as a Knative service, you must add the kogito-addons-quarkus-jobs-knative-eventing to your project and provide the proper configuration.
-
Dependency in the
pom.xml:
<dependency>
<groupId>org.kie.kogito</groupId>
<artifactId>kogito-addons-quarkus-jobs-knative-eventing</artifactId>
</dependency>-
Configuration parameters:
# Events produced by kogito-addons-quarkus-jobs-knative-eventing to program the timers on the Job Service.
mp.messaging.outgoing.kogito-job-service-job-request-events.connector=quarkus-http
mp.messaging.outgoing.kogito-job-service-job-request-events.url=${K_SINK:http://localhost:8280/jobs/events}
mp.messaging.outgoing.kogito-job-service-job-request-events.method=POST|
The |
Timeout showcase example
You can check Timeout example in Serverless Workflow to see how to use and configure workflows with timeouts.
Found an issue?
If you find an issue or any misleading information, please feel free to report it here. We really appreciate it!