Callbacks in SonataFlow
This document describes the Callback state and related examples. The Callback state performs an action and waits for an event, to be produced as a result of the action, to resume the workflow. The action peformed by a Callback state is an asynchronous external service invocation. Therefore, the Callback state is suitable to perform fire&wait-for-result operations.
From a workflow perspective, asynchronous service indicates that the control is returned to the caller immediately without waiting for the action to be completed. Once the action is completed, a CloudEvent is published to resume the workflow.
For the workflow to identify the published CloudEvent it is waiting for, the external service developer includes the workflow instance ID in the CloudEvent header or uses the Event correlation. The following figure displays the process:
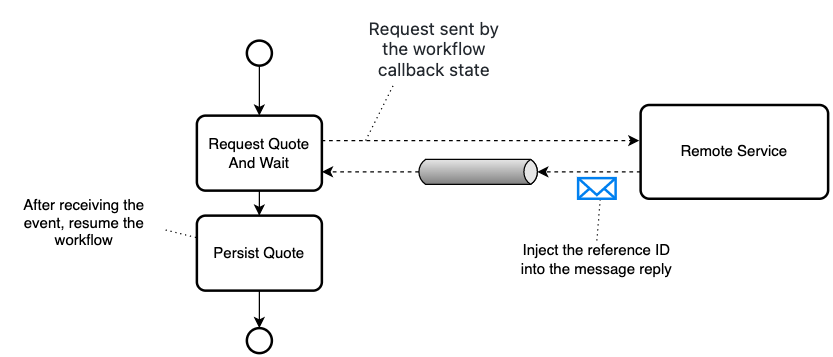
The workflow correlation described in this document focuses on the former mechanism that is based on the fact that each workflow instance contains a unique identifier, which is generated automatically.
Example of Callback state
To understand the Callback state, see the serverless-workflow-callback-quarkus example application in GitHub repository.
The initial model of the serverless-workflow-callback-quarkus example application is empty. Once the workflow is started, it publishes a CloudEvent of the resume type and waits for a CloudEvent, which contains the type wait.
A listener consumes the CloudEvent with the resume type and simulates the behavior of an external service. Consequently, on the external service side, when the actions associated with the resume type CloudEvent are completed, the listener publishes a wait type CloudEvent. Once the wait type CloudEvent is received, the workflow moves to the next state and ends successfully.
To use the Callback state in a workflow, first CloudEvent types such as resume and wait are declared that the workflow uses. Following is an example of CloudEvents declaration in a workflow definition:
"events": [
{
"name": "resumeEvent",
"source": "",
"type": "resume"
},
{
"name": "waitEvent",
"source": "",
"type": "wait"
}
]
After that, a Callback state is declared. The Callback state publishes a resume type CloudEvent and waits for a CloudEvent with wait type. The published CloudEvent contains a move data field, and the CloudEvent that is received is expected to contain a result data field. According to the eventDataFilter, the result data field is added to the workflow model as a move field.
Following is an example of declaring a Callback state that handles the wait type CloudEvent:
wait CloudEvent{
"name": "waitForEvent",
"type": "callback",
"action": {
"name": "publishAction",
"eventRef": {
"triggerEventRef": "resumeEvent",
"data": "{move: \"This is the initial data in the model\"}"
}
},
"eventRef": "waitEvent",
"eventDataFilter": {
"data": ".result",
"toStateData": ".move"
},
"transition": "finish"
}
An event listener consumes the resume type CloudEvent and publishes a new wait type CloudEvent. Following is an example of a Java method that publishes the wait type CloudEvent:
wait CloudEvent private String generateCloudEvent(String id, String input) {
Map<String, Object> eventBody = new HashMap<>();
eventBody.put("result", input + " and has been modified by the event publisher");
eventBody.put("dummyEventVariable", "This will be discarded by the process");
try {
return objectMapper.writeValueAsString(CloudEventBuilder.v1()
.withId(UUID.randomUUID().toString())
.withSource(URI.create(""))
.withType("wait")
.withTime(OffsetDateTime.now())
.withExtension(CloudEventExtensionConstants.PROCESS_REFERENCE_ID, id)
.withData(objectMapper.writeValueAsBytes(eventBody))
.build());
} catch (JsonProcessingException e) {
throw new IllegalArgumentException(e);
}
}
After that, the workflow application consumes the event published by the listener and sets the result field. The consumed CloudEvent contains an attribute named kogitoprocrefid, which holds the workflow instance ID of the workflow.
The kogitoprocrefid attribute is crucial because when the correlation is not used, then this attribute is the only way for the Callback state to identify that the related CloudEvent needs to be used to resume the workflow. For more information about correlation, see Event correlation in SonataFlow.
Note that each workflow is identified by a unique instance ID, which is automatically included in any published CloudEvent, as kogitoprocinstanceid CloudEvent extension.
The following example shows that the event listener takes the workflow instance ID of a workflow from a CloudEvent attribute named kogitoprocinstanceid, which is associated with the CloudEvent that is consumed.
resume CloudEvent @Incoming("in-resume")
@Outgoing("out-wait")
@Acknowledgment(Strategy.POST_PROCESSING)
public String onEvent(Message<String> message) {
Optional<CloudEvent> ce = CloudEventUtils.decode(message.getPayload());
JsonCloudEventData cloudEventData = (JsonCloudEventData) ce.get().getData();
return generateCloudEvent(ce.get().getExtension(CloudEventExtensionConstants.PROCESS_INSTANCE_ID).toString(), cloudEventData.getNode().get("move").asText());
}- Apache Kafka configuration in
serverless-workflow-callback-quarkus -
The
serverless-workflow-callback-quarkusexample application requires an external broker to manage the associated CloudEvents. The default setup in theserverless-workflow-callback-quarkusexample application uses Apache Kafka. However, you can also use Knative Eventing.Apache Kafka uses topics to publish or consume messages. In the
serverless-workflow-callback-quarkusexample application, two topics are used, matching the name of the CloudEvent types that are defined in the workflow, such asresumeandwait. TheresumeandwaitCloudEvent types are configured in theapplication.propertiesfile.For more information about using Apache Kafka with events, see Consuming and producing events using Apache Kafka.
Found an issue?
If you find an issue or any misleading information, please feel free to report it here. We really appreciate it!